
TL;DR
JupyterLabでGoogle Analytics(CSVファイル)をグラフ化してみる遊びをしてみて面白かったものの、一旦触らなくなりそうなのでメモ。
現状では全く役に立つレベルではない気がしますが、意外とハードル低く遊び始められるような感じがしました。
本当に初めて触りながら軽く遊んだ程度なので無駄な記述や誤りがあるかもしれません。ご容赦ください。
モチベーション
Webページのデザイン・UIの検討でウィンドウの最大幅、最小幅をどの範囲でサポートすべきか、というような話になり、既存サービスのアナリティクスデータを元に一度現状を把握しようと思ってCSVをDLしてみたもののCSVを見てもばらつきが視覚的によくわからないのでグラフにしようと思いました。
その時にそういえばこういうの統計系の本で読んだなと思って手を出してみました。
事前準備
ツール類のインストールについてはややこしいのでこの記事では触れないことにします。
-
JupyterLab
-
Python@3.x
- matplotlib
- Pandas
-
Google Analyticsのcsvをダウンロード
- ユーザー > テクノロジー > ブラウザとOSを開く
- グラフ下の画像の解像度タブを選択
- セカンダリディメンションでデバイスカテゴリを選択
- 画面右下「表示する行数」を1000行にする
- 画面右上のエクスポートからCSVをダウンロード
Jupyterで実装
最低限のcsvファイルの整形
不要データの削除
最初の方の見出しはこんなデータです
# ----------------------------------------
# すべてのウェブサイトのデータ
# ブラウザと OS
# 20190214-20190221
# ----------------------------------------
日別指標か何かはこんなデータです
日の指標,ユーザー
...
データの最後に数字の無いデータがあるのでこれも削除(してはだめなものかもしれない…)
,"1,195","1,108","1,477",33.11%,2.49,00:01:20,0.00%,0,$0.00
Headerの変換
日本語を打つのが面倒なので…適当に英語っぽく変換します
画面の解像度,デバイス カテゴリ,ユーザー,新規ユーザー,セッション,直帰率,ページ/セッション,平均セッション時間,コンバージョン率,目標の完了数,目標値
width_height,device,user,new_user,session,bounce_rate,page_session,avg_session_time,conversion,target_completion,target_value
Libraryの読み込み
# グラフ化に必要なものの準備
import matplotlib
import matplotlib.pyplot as plt
# データの扱いに必要なライブラリ
import pandas as pd
plt.style.use('ggplot')
データ整形
df = pd.read_csv('analytics.csv') # csv読み込み
df = df.dropna() # N/A値の除外
df['width'] = df.replace('x\d*', {'width_height': ''}, regex=True).width_height.values # width_height列からwidth部分を抜き出してカラムとして追加
df = df.astype({'width': 'int64'}) # 型をint64に変換する
df = df[df['device'].isin(['desktop'])] # deviceがdesktopのもののみにfilterする
df = df.reset_index() # indexを振り直す
df = df.sort_values(by=["width"], ascending=False) # ソートする
df = df.filter(items=['width', 'user']) # widthとuserだけのデータにフィルタする
df.head() # 最初の方のデータだけ表示
この時点でデータが上手く整形できていれば、このような感じのデータになります。
width user
41 4096 1
27 3840 2
11 3840 10
17 3440 4
26 3200 2
グラフの描画と書き出し
2グラフ1画像にしたかったのですが、中々上手く出来ずばらばらに…。
plt.figure()
df.hist(bins=20, column="width", density=True, color='orange', range=(580, 1980))
plt.savefig('./export/hist.png')
df.plot(kind='kde', style='r--', y=df.columns[0], x=df.columns[1])
plt.savefig('./export/plot.png')
plt.show()
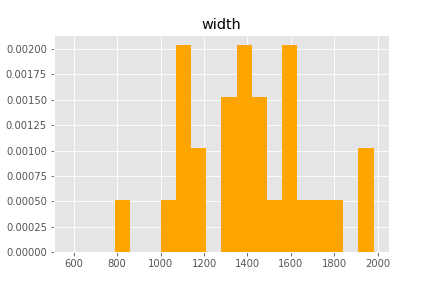
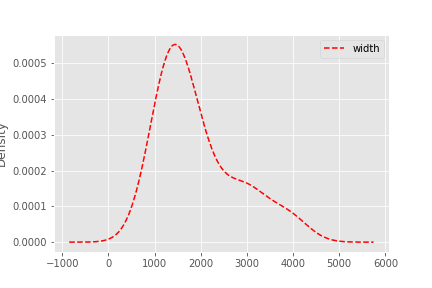
結果
こんな感じのグラフが表示されます。
データ量が少ないのでなんともですが、大体1980幅で作業しているのですが、1000-1200のゾーンにもユーザーが多くいるので、この幅もちゃんとサポートする必要があることがぱっと見でわかりますね。
おわりに
ということで、DLしてからのデータ整形の自動化など、まだまだ自動化できる部分が多いかと思いますが、ある程度簡単にグラフ化ができて楽しかったです。
まだまだ先がある分野なので、また余裕ができたらこういう系の特化している本もありそうなので一通り勉強したいと思いました。
結果はあれですが、どなたが興味と持つきっかけになれば幸いです!